There is a kind of psychology research article I have seen many times over the past 20 years. My pet name for it is the “ACE” because it goes like this:
- Archival
- Correlational
- Experimental

These three phases, in that order, each with one or more studies. To invent an example, imagine we’re testing whether swearing makes you more likely to throw things … via a minimal ACE article.
(To my knowledge, there is no published work on this topic, but mea culpa if this idea is your secret baby.)
First, give me an “A” — Archival! We choose to dig up the archives of the US Tennis Association, covering all major matches from 1999 to 2007. Lucky for us, they have kept records of unsporting incidents for each player at each match, including swearing and throwing the racket. Using multilevel statistics, we find that indeed, the more a player curses in a match, the more they throw the racket. The effect size is a healthy r = .50, p < .001.
Now, give me a “C” — Correlational! We give 300 online workers a questionnaire, where we ask how often they have cursed in the last 7 days, and how often they have thrown something in anger in the same time period. The two measures are correlated r = .17, p = .003.
Finally, give me an “E” — Experimental! We bring 100 undergraduates into the lab. We get half of them to swear profusely for one full minute, the other half to rattle off as many names of fish as they can think of. We then let them throw squash balls against a target electronically emblazoned with the face of their most hated person, a high-tech update of the dart task in Rozin, Millman and Nemeroff (1986). And behold, the balls fly faster and harder in the post-swearing condition than in the post-fish condition, t(98) = 2.20, d=0.44, p = .03.
Aesthetically, this model is pleasing. It embraces a variety of settings and populations, from the most naturalistic (tennis) to the most constrained (the lab). It progresses by eliminating confounds. We start with two settings, the Archival and Correlational, where throwing and cursing stand in an uncertain relation to each other. Their association, after all, could just be a matter of causation going either way, or third variables causing both. The Experiment makes it clearer. The whole package presents a compelling, full-spectrum accumulation of proof for the hypothesis. After all, the results are all significant, right?
But in the new statistical era, we care about more than just the significance of individual studies. We care about effect size across the studies. Effect size helps us integrate the evidence from non-significant studies and significant ones, under standards of full reporting. It goes into meta-analyses, both within the article and on a larger scale. It lets us calculate the power of the studies, informing analyses of robustness such as p-curve and R-index.
Effect sizes, however, are critically determined by the methods used to generate them. I would bet that many psychologists think about effect size as some kind of Platonic form, a relationship between variables in the abstract state. But effect size cannot be had except through research methods. And methods can:
- give the appearance of a stronger effect than warranted, through confounding variables;
- or obscure an effect that actually exists, through imprecision and low power.
So, it’s complicated to extract a summary effect size from the parts of an ACE. The archival part, and to some extent the correlational, will have lots of confounding. More confounds may remain even after controlling for the obvious covariates. Experimental data may suffer from measurement noise, especially if subtle or field methods are used.
And, indeed, all parts might yield an inflated estimate if results and analyses are chosen selectively. The archival part is particularly prone to suspicions of post-hoc peeking. Why those years and not other ones? Why thrown tennis rackets and not thrown hockey sticks? Why Larry the lawyer and Denise the dentist, but not Donna the doctor or Robbie the rabbi (questions asked of research into the name-letter effect; Gallucci, 2003, pdf)? Pre-registration of these decisions, far from being useless for giving confidence in archival studies, almost seems like a requirement, provided it happens before the data are looked at in depth.
The ACE’s appeal requires studies with quite different methods. When trying to subject it to p-curves, mini-meta-analyses (Goh, Hall & Rosenthal, 2016; pdf), or other aggregate “new statistics,” we throw apples and oranges in the blender together. If evidence from the experiment is free from confounds but statistically weak, and the evidence from the archival study is statistically strong and big but full of confounds, does the set of studies really show both strong and unconfounded evidence?
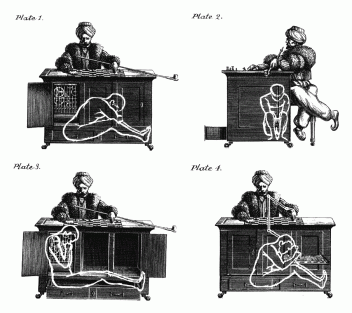
The 18th century showman Wolfgang von Kempelen had a way to convince spectators there was no human agent inside his chess-playing “automaton”. He would open first one cabinet, then the other, while the human player inside moved his torso into the concealed parts. At no time was the automaton (yes, the famous “Mechanical Turk“) fully open for view. Likewise, the ACE often has no study that combines rigorous method with robust finding. So, it’s hard to know what conclusions we should draw about effect size and significance on an article-wise level.
Leif Nelson at the Data Colada blog has recently taken a pessimistic view on finding the true effect size behind any research question. As he argues, the effect size has to take into account all possible studies that could have been run. So, evidence about it will always be incomplete.
Still, I think a resolution is possible, if we understand the importance of method. Yes, the best effect size takes into account both underlying effect and method used. But not all methods are equal. To have the clearest view of an underlying effect, we should focus on those methods that best meet the two criteria above: the least confounded with other factors, while at the same time being the most precise, sensitive, and free from error.
I said “possible,” not “easy.” For the first criterion, we need some agreement about which factors are confounds, and which are part of the effect. For example, we show that science knowledge correlates with a “liberal”-“conservative” political self-report item. Then, trying to eliminate confounds, we covary out religious fundamentalism, right-wing authoritarianism, and support for big government. The residual of the lib-con item now represents a strange “liberal” who by statistical decree is just as likely as an equally strange “conservative” to be an anti-government authoritarian fundamentalist. In trying to purify a concept, you can end up washing it clean away.
Experimental methods make it somewhat easier to isolate an effect, but even then controversy might swirl around whether the effect has been whittled down to something too trivial or ecologically invalid to matter. A clear definition of the effect is also necessary in experiments. For example, whether you see implicit manipulations as the ultimate test of an effect depends on how much you see participant awareness and demand as part of the effects, or part of the problem. And are we content to look at self-reports of mental phenomena, or do we demand a demonstration of (messier? noisier?) behavioral effects as well? Finally, the effect size is going to be larger if you are only interested in the strength of an intervention versus no intervention — in which case, bring on the placebo effect, if it helps! It will usually be smaller, though, if you are interested in theoretically nailing down the “active ingredient” in that intervention.
The second criterion of precision is better studied. Psychometricians already know a lot about reducing noise in studies through psychometric validation. Indeed, there is a growing awareness that the low reliability and validity of many measures and manipulations in psychological research is a problem (Flake, Pek & Hehman, 2017, pdf). Even if the process of testing methods for maximum reliability is likely to be tedious, it is, theoretically, within our grasp.
But in a final twist, these two criteria often work against each other in research. Trying to reach good statistical power, it is harder to run large numbers of participants in controlled lab experiments than in questionnaire or archival data collections. Trying to avoid participant awareness confounds, implicit measures often increase measurement “noise” (Gawronski & De Houwer, 2014; Krause et al., 2011). This means it will be hard to get agreement about what method simultaneously maximizes the clarity of the effect and its construct validity. But the alternative is pessimism about the meaning of the effect size, and a return to direction-only statistics.
I’ll conclude, boldly. It is meaningless to talk about the aggregate effect size in an ACE-model article, or to apply any kind of aggregate test to it that depends on effect sizes, such as p-curve. The results will depend, arbitrarily, on how many studies are included using each kind of method. A litmus test: would these studies all be eligible for inclusion in a single quantative meta-analysis? Best practice in meta-analysis demands that we define carefully the design of studies for inclusion, so that they are comparable with each other. Knowing what we know about methodology and effect size, the article, like the meta-analysis, is only a valid unit of aggregation if its studies’ methods are comparable with each other. The ACE article presents a compelling variety of methods and approaches, but that very quality is its Achilles’ heel when it comes to the “new statistics.”